전국 도시공원 데이터 프로젝트
사용할 라이브러리 import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns한글폰트 설치 및 등록
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
plt.rc("font", family="NanumBarunGothic")
사용할 전국 도시공원 데이터셋
park = pd.read_csv("/content/drive/MyDrive/데이터분석/전국도시공원표준데이터 (2).csv", encoding="ms949")
park.head()
행, 열 개수 확인
park.shape # (18137, 20)
간략한 정보 확인
park.info()
결측값 확인
park.isnull().sum()
컬럼 확인
park.columns
필요없는 컬럼 제거
# inplace=Ture로 재할당 하지 않아도 즉시 적용
park.drop(columns=['공원보유시설(운동시설)', '공원보유시설(유희시설)', '공원보유시설(편익시설)', '공원보유시설(교양시설)','공원보유시설(기타시설)', '지정고시일', '관리기관명', 'Unnamed: 19'], inplace=True)
잘 제거 되었는지 head()로 확인
park.head()
위치를 기준으로 산점도 그래프 그리기
# x축은 '위도', y축은 '경도'로 산점도 그래프 그리기
park.plot.scatter(x="경도", y="위도", figsize=(8,10), grid=True)
boxplot으로 위도의 이상치 확인
sns.boxplot(y=park["위도"])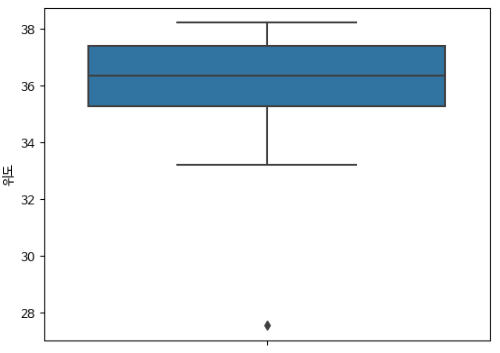
boxplot으로 경도의 이상치 확인
sns.boxplot(y=park["경도"])
이상치가 예상되는 데이터 확인
# 시리즈 비교 : |, & 사용
# 위도가 32도보다 작거나, 경도가 132도보다 큰 데이터 출력
park.loc[(park["위도"] < 32) | (park["경도"] > 132)]
이상치가 예상되는 데이터 따로 저장
# park_loc_error에 이상치로 예상되는 데이터 넣기
park_loc_error = park.loc[(park["위도"] < 32) | (park["경도"] > 132)]
올바른 데이터만 추출
park = park.loc[(park["위도"] >= 32) | (park["경도"] <= 132)]
shape 확인
park.shape # (18137, 12)
"공원면적비율" 파생변수 만들기
# sqrt(공원면적) * 0.01를 람다식으로 사용하여 공원면적비율 구하기
park["공원면적비율"] = park["공원면적"].apply(lambda x : np.sqrt(x) * 0.01)
head 확인
park.head()
"도로명 주소"는 입력되지 않고, "지번 주소"만 입력된 데이터를 확인
# "소재지도로명주소"는 결측값이고, "소재지지번주소"는 결측값이 아닌 데이터 출력
park.loc[park["소재지도로명주소"].isnull() & park["소재지지번주소"].notnull()]
"도로명 주소"와 "지번 주소"가 모두 입력된 데이터를 확인
park.loc[park["소재지도로명주소"].notnull() & park["소재지지번주소"].notnull()]
"도로명 주소"와 "지번 주소"가 모두 입력되지 않은 데이터를 확인
park.loc[park["소재지도로명주소"].isnull() & park["소재지지번주소"].isnull()]
도로명 주소가 입력되지 않은 데이터를 지번 주소로 대신 채움
# inplace=True로 즉시 적용
park["소재지도로명주소"].fillna(park["소재지지번주소"], inplace=True)
head 확인
park.head()
'도로명주소'에서 "시도"만 추출하여 "시도" 파생변수 만들기
1. '도로명주소' 컬럼에서 '시도' 값 인덱스 찾아보기
# split(' ', expand=True) : 데이터프레임으로 해당 데이터가 분리되고 인덱싱과 슬라이싱이 가능
# 0 1 2 3
# 부산광역시 강서구 구랑동 1199-7
park["소재지도로명주소"].str.split(' ', expand=True)
2. '시도' 파생변수 만들고, 추출한 '시도' 대입
park["시도"] = park["소재지도로명주소"].str.split(' ', expand=True)[0]
head 확인
park.head()
'시도' 컬럼 값 종류 확인
park["시도"].value_counts()
'시도'에 '강원'을 '강원도'로 변경
park["시도"][park["시도"] == "강원"] = "강원도"
'시도' 컬럼 값 종류 재확인
park["시도"].value_counts()
시도를 기준으로 산점도 그래프 그리기
plt.figure(figsize=(8, 10))
# 사용할 데이터프레임: park
# x축: 경도, y축: 위도
# '시도' 컬럼에 따라 색상 구분하여 표기
sns.scatterplot(data=park, x="경도", y="위도", hue="시도")
'시도별 합계 데이터 저장
park_sido = pd.DataFrame(park["시도"].value_counts())
park_sido
전체 합계에 대한 '시도'별 비율 데이터 저장
# value_counts(normalize=True): 전체 합계에 대한 비율이 계산
park_sido_normalize = pd.DataFrame(park["시도"].value_counts(normalize=True))
park_sido_normalize
시도별 합계 데이터(park_sido)와 비율 데이터(park_sido_normalize)를 병합
# left_index=True, right_index=True 를 사용하여 index를 기준으로 병합하고,
# reset_index()를 사용하여 병합 후 인덱스 리셋
park_sido = park_sido.merge(park_sido_normalize, left_index=True, right_index=True).reset_index()
park_sido
컬럼명 다시 설정
park_sido.columns= ["시도", "합계", "평균"]
park_sido
'시도'별 도시공원 합계를 막대 그래프로 그리기
plt.figure(figsize=(12,8))
plt.xticks(rotation=45)
sns.barplot(data=park_sido, x="시도", y="합계")
plt.figure(figsize=(12,8))
sns.barplot(data=park_sido, x="합계", y="시도")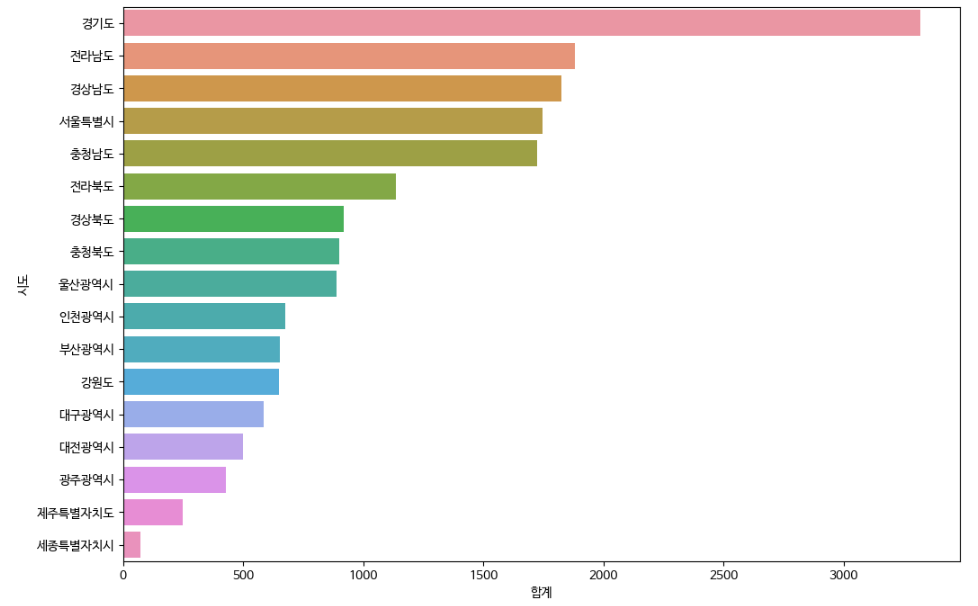
'데이터 분석' 카테고리의 다른 글
| 12.스타벅스 API를 이용한 프로젝트 (1) | 2023.06.15 |
|---|---|
| 11. 따릉이 API를 이용한 프로젝트 (0) | 2023.06.15 |
| 9. 상권별 업종 밀집 통계 프로젝트 (0) | 2023.06.14 |
| 8. folium (0) | 2023.06.14 |
| 7. 워드 클라우드(Word Cloud) (0) | 2023.06.13 |



